27 Mini-projets¶
Dans ce chapitre, nous vous proposons quelques scénarios pour développer vos compétences en Python et mettre en œuvre les concepts que vous avez rencontrés dans les chapitres précédents.
27.1 Description des projets¶
27.1.1 Mots anglais dans le protéome humain¶
L'objectif de ce premier projet est de découvrir si des mots anglais peuvent se retrouver dans les séquences du protéome humain, c'est-à-dire dans les séquences de l'ensemble des protéines humaines.
Vous aurez à votre disposition :
- Le fichier
english-common-words.txt, qui contient les 3 000 mots anglais les plus fréquents, à raison d'1 mot par ligne. - Le fichier
human-proteome.fastaqui contient le protéome humain sous la forme de séquences au format FASTA. Attention, ce fichier est assez gros. Ce fichier provient de la banque de données UniProt à partir de cette page.
Des explications sur le format FASTA et des exemples de code sont fournis dans l'annexe A Quelques formats de données en biologie.
27.1.2 Genbank2fasta¶
Ce projet consiste à écrire un convertisseur de fichier, du format GenBank au format FASTA.
Pour cela, nous allons utiliser le fichier GenBank du chromosome I de la levure de boulanger Saccharomyces cerevisiae. Vous pouvez télécharger ce fichier :
- soit via le lien sur le site du cours
NC_001133.gbk; - soit directement sur la page de Saccharomyces cerevisiae S288c chromosome I, complete sequence sur le site du NCBI, puis en cliquant sur Send to, puis Complete Record, puis Choose Destination: File, puis Format: GenBank (full) et enfin sur le bouton Create File.
Vous trouverez des explications sur les formats FASTA et GenBank ainsi que des exemples de code dans l'annexe A Quelques formats de données en biologie.
Vous pouvez réaliser ce projet sans ou avec des expressions régulières (abordées dans le chapitre 17).
27.1.3 Simulation d'un pendule¶
On se propose de réaliser une simulation d'un pendule simple en Tkinter. Un pendule simple est représenté par une masse ponctuelle (la boule du pendule) reliée à un pivot immobile par une tige rigide et sans masse. On néglige les effets de frottement et on considère le champ gravitationnel comme uniforme. Le mouvement du pendule sera calculé en résolvant numériquement l'équation différentielle suivante :
où \(\theta\) représente l'angle entre la verticale et la tige du pendule, \(a_{\theta}\) l'accélération angulaire, \(g\) la gravité, et \(l\) la longueur de la tige (note : pour la dérivation d'une telle équation vous pouvez consulter la page wikipedia ou l'accompagnement pas à pas, cf. la rubrique suivante).
Pour trouver la valeur de \(\theta\) en fonction du temps, on pourra utiliser la méthode semi-implicite d'Euler de résolution d'équation différentielle. La formule ci-dessus donne l'accélération angulaire au temps t : \(a_{\theta}(t) = -\frac{g}{l} \times sin(\theta(t))\). À partir de celle-ci, la méthode propose le calcul de la vitesse angulaire au pas suivant : \(v_{\theta}(t + \delta t) = v_{\theta}(t) + a_{\theta}(t) \times \delta t\) (où \(\delta t\) représente le pas de temps entre deux étapes successives de la simulation). Enfin, cette vitesse \(v_{\theta}(t + \delta t)\) donne l'angle \(\theta\) au pas suivant : \(\theta (t + \delta t) = \theta (t) + v_{\theta}(t + \delta t) \times \delta t\). On prendra un pas de temps \(\delta t\) = 0.05 s, une accélération gravitationnelle \(g\) = 9.8 m.s\(^{-2}\) et une longueur de tige de \(l\) = 1 m.
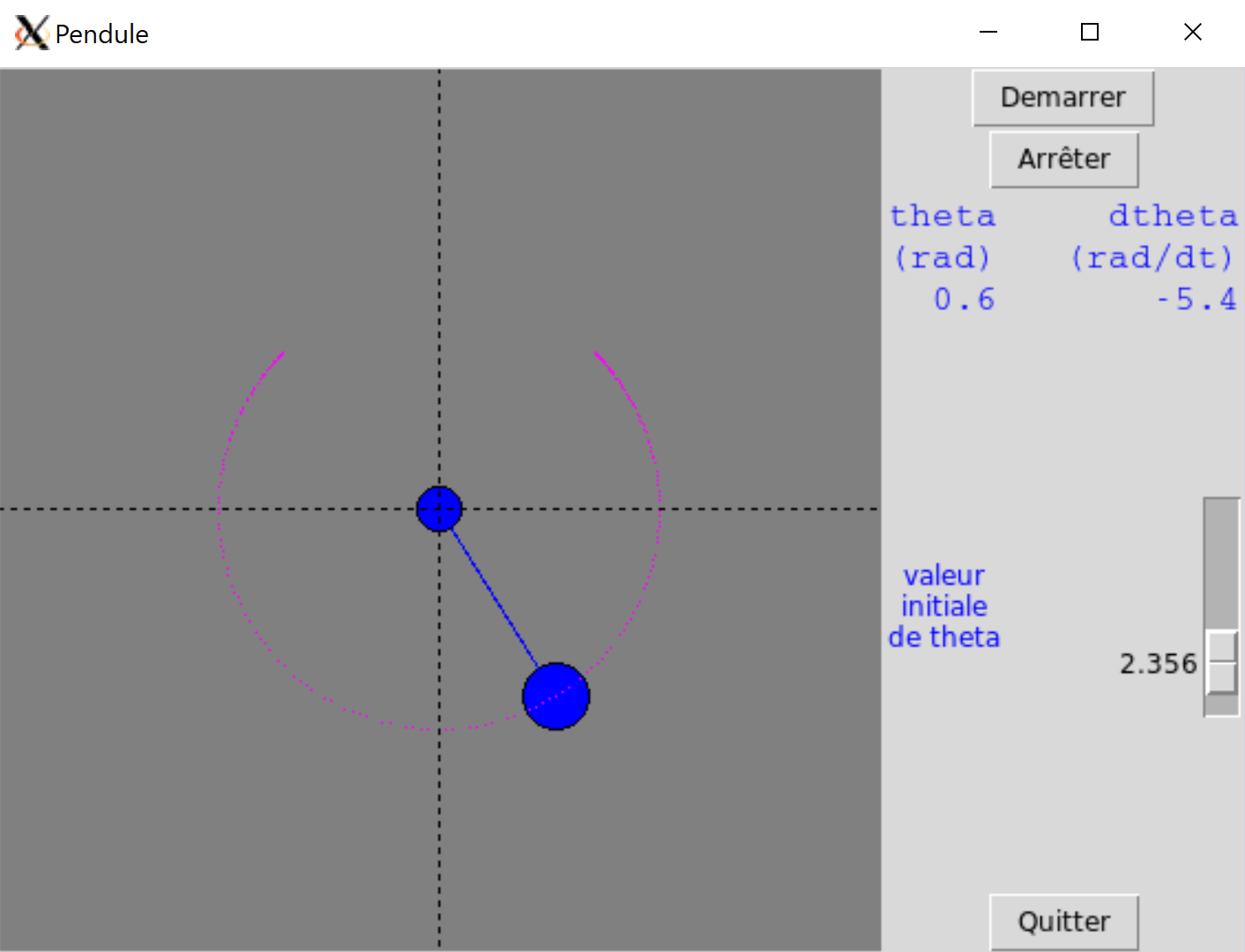
Pour la visualisation, vous pourrez utiliser le widget canvas du module Tkinter (voir le chapitre 25 Fenêtres graphiques et Tkinter (en ligne), rubrique Un canvas animé dans une classe). On cherche à obtenir un résultat comme montré dans la figure 1.
Nous vous conseillons de procéder d'abord à la mise en place du simulateur physique (c'est-à-dire obtenir \(\theta\) en fonction du temps ou du pas de simulation). Faites par exemple un premier script Python qui produit un fichier à deux colonnes (temps et valeur de \(\theta\)). Une fois que cela fonctionne bien, il vous faudra construire l'interface Tkinter et l'animer. Vous pouvez ajouter un bouton pour démarrer / stopper le pendule et une règle pour modifier sa position initiale.
N'oubliez pas, il faudra mettre dans votre programme final une fonction qui convertit l'angle \(\theta\) en coordonnées cartésiennes \(x\) et \(y\) dans le plan du canvas. Faites également attention au système de coordonnées du canvas où les ordonnées sont inversées par rapport à un repère mathématique. Pour ces deux aspects, reportez-vous à l'exercice Polygone de Sierpinski du chapitre 25 Fenêtres graphiques et Tkinter (en ligne).
27.2 Accompagnement pas à pas¶
Vous trouverez ci-après les différentes étapes pour réaliser les mini-projets proposés. Prenez le temps de bien comprendre une étape avant de passer à la suivante.
27.2.1 Mots anglais dans le protéome humain¶
L'objectif de ce premier projet est de découvrir si des mots anglais peuvent se retrouver dans les séquences du protéome humain, c'est-à-dire dans les séquences de l'ensemble des protéines humaines.
Composition aminée¶
Dans un premier temps, composez 5 mots anglais avec les 20 acides aminés.
Des mots¶
Téléchargez le fichier english-common-words.txt. Ce fichier contient les 3000 mots anglais les plus fréquents, à raison d'1 mot par ligne.
Créez un script words_in_proteome.py et écrivez la fonction read_words() qui va lire les mots contenus dans le fichier dont le nom est fourni en argument du script et renvoyer une liste contenant les mots convertis en majuscule et composés de 3 caractères ou plus.
Dans le programme principal, affichez le nombre de mots sélectionnés.
Des protéines¶
Téléchargez maintenant le fichier human-proteome.fasta. Attention, ce fichier est assez gros. Ce fichier provient de la banque de données UniProt à partir de cette page.
Voici les premières lignes de ce fichier ([...] indique une coupure que nous avons faite) :
>sp|O95139|NDUB6_HUMAN NADH dehydrogenase [ubiquinone] 1 beta [...]
MTGYTPDEKLRLQQLRELRRRWLKDQELSPREPVLPPQKMGPMEKFWNKFLENKSPWRKM
VHGVYKKSIFVFTHVLVPVWIIHYYMKYHVSEKPYGIVEKKSRIFPGDTILETGEVIPPM
KEFPDQHH
>sp|O75438|NDUB1_HUMAN NADH dehydrogenase [ubiquinone] 1 beta [...]
MVNLLQIVRDHWVHVLVPMGFVIGCYLDRKSDERLTAFRNKSMLFKRELQPSEEVTWK
>sp|Q8N4C6|NIN_HUMAN Ninein OS=Homo sapiens OX=9606 GN=NIN PE=1 SV=4
MDEVEQDQHEARLKELFDSFDTTGTGSLGQEELTDLCHMLSLEEVAPVLQQTLLQDNLLG
RVHFDQFKEALILILSRTLSNEEHFQEPDCSLEAQPKYVRGGKRYGRRSLPEFQESVEEF
PEVTVIEPLDEEARPSHIPAGDCSEHWKTQRSEEYEAEGQLRFWNPDDLNASQSGSSPPQ
Toujours dans le script words_in_proteome.py, écrivez la fonction read_sequences() qui va lire le protéome dans le fichier dont le nom est fourni en second argument du script. Cette fonction va renvoyer un dictionnaire dont les clefs sont les identifiants des protéines (par exemple, O95139, O75438, Q8N4C6) et dont les valeurs associées sont les séquences.
Dans le programme principal, affichez le nombre de séquences lues.
À des fins de test, affichez également la séquence associée à la protéine O95139.
À la pêche aux mots¶
Écrivez maintenant la fonction search_words_in_proteome() qui prend en argument la liste de mots et le dictionnaire contenant les séquences des protéines et qui va compter le nombre de séquences dans lesquelles un mot est présent. Cette fonction renverra un dictionnaire dont les clefs sont les mots et les valeurs le nombre de séquences qui contiennent ces mots. La fonction affichera également le message suivant pour les mots trouvés dans le protéome :
Cette étape prend quelques minutes. Soyez patient.
Et le mot le plus fréquent est...¶
Pour terminer, écrivez maintenant la fonction find_most_frequent_word() qui prend en argument le dictionnaire renvoyé par la précédente fonction search_words_in_proteome() et qui affiche le mot trouvé dans le plus de protéines, ainsi que le nombre de séquences dans lesquelles il a été trouvé, sous la forme :
Quel est ce mot ?
Quel pourcentage des séquences du protéome contiennent ce mot ?
Pour être plus complet¶
Jusqu'à présent, nous avions déterminé, pour chaque mot, le nombre de séquences dans lesquelles il apparaissait. Nous pourrions aller plus loin et calculer aussi le nombre de fois que chaque mot apparaît dans les séquences.
Pour cela modifier la fonction search_words_in_proteome() de façon à compter le nombre d’occurrences d'un mot dans les séquences.
La méthode .count() vous sera utile.
Déterminez alors quel mot est le plus fréquent dans le protéome humain.
27.2.2 genbank2fasta (sans expression régulière)¶
Ce projet consiste à écrire un convertisseur de fichier, du format GenBank au format FASTA. L'annexe A Quelques formats de données en biologie rappelle les caractéristiques de ces deux formats de fichiers.
Le jeu de données avec lequel nous allons travailler est le fichier GenBank du chromosome I de la levure du boulanger Saccharomyces cerevisiae. Les indications pour le télécharger sont indiqués dans la description du projet.
Dans cette rubrique, nous allons réaliser ce projet sans expression régulière.
Lecture du fichier¶
Créez un script genbank2fasta.py et créez la fonction lit_fichier() qui prend en argument le nom du fichier et qui renvoie le contenu du fichier sous forme d'une liste de lignes, chaque ligne étant elle-même une chaîne de caractères.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de lignes lues.
Extraction du nom de l'organisme¶
Dans le même script, ajoutez la fonction extrait_organisme() qui prend en argument le contenu du fichier précédemment obtenu avec la fonction lit_fichier() (sous la forme d'une liste de lignes) et qui renvoie le nom de l'organisme. Pour récupérer la bonne ligne vous pourrez tester si les premiers caractères de la ligne contiennent le mot-clé ORGANISM.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nom de l'organisme.
Recherche des gènes¶
Dans le fichier GenBank, les gènes sens sont notés de cette manière :
ou
et les gènes antisens (ou encore complémentaires) de cette façon :
ou
Les valeurs numériques séparées par .. indiquent la position du gène dans le génome (numéro de la première base, numéro de la dernière base).
Le symbole < indique un gène partiel sur l'extrémité 5', c'est-à-dire que le codon START correspondant est incomplet. Respectivement, le symbole > désigne un gène partiel sur l'extrémité 3', c'est-à-dire que le codon STOP correspondant est incomplet. Pour plus de détails, consultez la documentation du NCBI sur les délimitations des gènes. Nous vous proposons ici d'ignorer ces symboles > et <.
Repérez ces différents gènes dans le fichier NC_001133.gbk. Pour récupérer ces lignes de gènes il faut tester si la ligne commence par
(c'est-à-dire 5 espaces, suivi du mot gene, suivi de 12 espaces). Pour savoir s'il s'agit d'un gène sur le brin direct ou complémentaire, il faut tester la présence du mot complement dans la ligne lue.
Ensuite si vous souhaitez récupérer la position de début et de fin de gène, nous vous conseillons d'utiliser la fonction replace() et de ne garder que les chiffres et les . Par exemple
sera transformé en
Enfin, avec la méthode .split() vous pourrez facilement récupérer les deux entiers de début et de fin de gène.
Dans le même script genbank2fasta.py, ajoutez la fonction recherche_genes() qui prend en argument le contenu du fichier (sous la forme d'une liste de lignes) et qui renvoie la liste des gènes.
Chaque gène sera lui-même une liste contenant le numéro de la première base, le numéro de la dernière base et une chaîne de caractère "sens" pour un gène sens et "antisens" pour un gène antisens.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de gènes trouvés, ainsi que le nombre de gènes sens et antisens.
Extraction de la séquence nucléique du génome¶
La taille du génome est indiqué sur la première ligne d'un fichier GenBank. Trouvez la taille du génome stocké dans le fichier NC_001133.gbk.
Dans un fichier GenBank, la séquence du génome se trouve entre les lignes
et
Trouvez dans le fichier NC_001133.gbk la première et dernière ligne de la séquence du génome.
Pour récupérer les lignes contenant la séquence, nous vous proposons d'utiliser un algorithme avec un drapeau is_dnaseq (qui vaudra True ou False). Voici l'algorithme proposé en pseudo-code :
is_dnaseq <- False
Lire chaque ligne du fichier gbk
si la ligne contient "//"
is_dnaseq <- False
si is_dnaseq vaut True
accumuler la séquence
si la ligne contient "ORIGIN"
is_dnaseq <- True
Au début ce drapeau aura la valeur False. Ensuite, quand il se mettra à True, on pourra lire les lignes contenant la séquence, puis quand il se remettra à False on arrêtera.
Une fois la séquence récupérée, il suffira d'éliminer les chiffres, retours chariots et autres espaces (Conseil : calculer la longueur de la séquence et comparer la à celle indiquée dans le fichier gbk).
Toujours dans le même script genbank2fasta.py, ajoutez la fonction extrait_sequence() qui prend en argument le contenu du fichier (sous la forme de liste de lignes) et qui renvoie la séquence nucléique du génome (dans une chaîne de caractères). La séquence ne devra pas contenir d'espaces, ni de chiffres ni de retours chariots.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de bases de la séquence extraite. Vérifiez que vous n'avez pas fait d'erreur en comparant la taille de la séquence extraite avec celle que vous avez trouvée dans le fichier GenBank.
Construction d'une séquence complémentaire inverse¶
Toujours dans le même script, ajoutez la fonction construit_comp_inverse() qui prend en argument une séquence d'ADN sous forme de chaîne de caractères et qui renvoie la séquence complémentaire inverse (également sous la forme d'une chaîne de caractères).
On rappelle que construire la séquence complémentaire inverse d'une séquence d'ADN consiste à :
- Prendre la séquence complémentaire. C'est-à-dire remplacer la base
apar la baset,tpara,cpargetgparc. - Prendre l'inverse. C'est-à-dire que la première base de la séquence complémentaire devient la dernière base et réciproquement, la dernière base devient la première.
Pour vous faciliter le travail, ne travaillez que sur des séquences en minuscule.
Testez cette fonction avec les séquences atcg, AATTCCGG et gattaca.
Écriture d'un fichier FASTA¶
Toujours dans le même script, ajoutez la fonction ecrit_fasta() qui prend en argument un nom de fichier (sous forme de chaîne de caractères), un commentaire (sous forme de chaîne de caractères) et une séquence (sous forme de chaîne de caractères) et qui écrit un fichier FASTA. La séquence sera à écrire sur des lignes ne dépassant pas 80 caractères.
Pour rappel, un fichier FASTA suit le format suivant :
>commentaire
sequence sur une ligne de 80 caractères maxi
suite de la séquence .......................
suite de la séquence .......................
...
Testez cette fonction avec :
- nom de fichier :
test.fasta - commentaire :
mon commentaire -
séquence :
atcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatc
Extraction des gènes¶
Toujours dans le même script, ajoutez la fonction extrait_genes() qui prend en argument la liste des gènes, la séquence nucléotidique complète (sous forme d'une chaîne de caractères) et le nom de l'organisme (sous forme d'une chaîne de caractères) et qui pour chaque gène :
- extrait la séquence du gène dans la séquence complète ;
- prend la séquence complémentaire inverse (avec la fonction
construit_comp_inverse()si le gène est antisens ; - enregistre le gène dans un fichier au format FASTA (avec la fonction
ecrit_fasta()) ; - affiche à l'écran le numéro du gène et le nom du fichier FASTA créé.
La première ligne des fichiers FASTA sera de la forme :
Le numéro du gène sera un numéro consécutif depuis le premier gène jusqu'au dernier. Il n'y aura pas de différence de numérotation entre les gènes sens et les gènes antisens.
Testez cette fonction avec le fichier GenBank NC_001133.gbk.
Assemblage du script final¶
Pour terminer, modifiez le script genbank2fasta.py de façon à ce que le fichier GenBank à analyser (dans cet exemple NC_001133.gbk), soit entré comme argument du script.
Vous afficherez un message d'erreur si :
- le script
genbank2fasta.pyest utilisé sans argument, - le fichier fourni en argument n'existe pas.
Pour vous aider, n'hésitez pas à jeter un œil aux descriptions des modules sys et pathlib dans le chapitre 9 Modules.
Testez votre script ainsi finalisé.
Bravo, si vous êtes arrivés jusqu'à cette étape.
27.2.3 genbank2fasta (avec expressions régulières)¶
Ce projet consiste à écrire un convertisseur de fichier, du format GenBank au format FASTA. L'annexe A Quelques formats de données en biologie rappelle les caractéristiques de ces deux formats de fichiers.
Le jeu de données avec lequel nous allons travailler est le fichier GenBank du chromosome I de la levure du boulanger Saccharomyces cerevisiae. Les indications pour le télécharger sont indiqués dans la description du projet.
Dans cette rubrique, nous allons réaliser ce projet avec des expressions régulières en utilisant le module re.
Lecture du fichier¶
Créez un script genbank2fasta.py et créez la fonction lit_fichier() qui prend en argument le nom du fichier et qui renvoie le contenu du fichier sous forme d'une liste de lignes, chaque ligne étant elle-même une chaîne de caractères.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de lignes lues.
Extraction du nom de l'organisme¶
Dans le même script, ajoutez la fonction extrait_organisme() qui prend en argument le contenu du fichier précédemment obtenu avec la fonction lit_fichier() (sous la forme d'une liste de lignes) et qui renvoie le nom de l'organisme. Utilisez de préférence une expression régulière.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nom de l'organisme.
Recherche des gènes¶
Dans le fichier GenBank, les gènes sens sont notés de cette manière :
ou
et les gènes antisens de cette façon :
ou
Les valeurs numériques séparées par .. indiquent la position du gène dans le génome (numéro de la première base, numéro de la dernière base).
Le symbole < indique un gène partiel sur l'extrémité 5', c'est-à-dire que le codon START correspondant est incomplet. Respectivement, le symbole > désigne un gène partiel sur l'extrémité 3', c'est-à-dire que le codon STOP correspondant est incomplet. Pour plus de détails, consultez la documentation du NCBI sur les délimitations des gènes.
Repérez ces différents gènes dans le fichier NC_001133.gbk. Construisez deux expressions régulières pour extraire du fichier GenBank les gènes sens et les gènes antisens.
Modifiez ces expressions régulières pour que les numéros de la première et de la dernière base puissent être facilement extraits.
Dans le même script genbank2fasta.py, ajoutez la fonction recherche_genes() qui prend en argument le contenu du fichier (sous la forme d'une liste de lignes) et qui renvoie la liste des gènes.
Chaque gène sera lui-même une liste contenant le numéro de la première base, le numéro de la dernière base et une chaîne de caractère "sens" pour un gène sens et "antisens" pour un gène antisens.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de gènes trouvés, ainsi que le nombre de gènes sens et antisens.
Extraction de la séquence nucléique du génome¶
La taille du génome est indiqué sur la première ligne d'un fichier GenBank. Trouvez la taille du génome stocké dans le fichier NC_001133.gbk.
Dans un fichier GenBank, la séquence du génome se trouve entre les lignes
et
Trouvez dans le fichier NC_001133.gbk la première et dernière ligne de la séquence du génome.
Construisez une expression régulière pour extraire du fichier GenBank les lignes correspondantes à la séquence du génome.
Modifiez ces expressions régulières pour que la séquence puisse être facilement extraite.
Toujours dans le même script, ajoutez la fonction extrait_sequence() qui prend en argument le contenu du fichier (sous la forme de liste de lignes) et qui renvoie la séquence nucléique du génome (dans une chaîne de caractères). La séquence ne devra pas contenir d'espaces.
Testez cette fonction avec le fichier GenBank NC_001133.gbk et affichez le nombre de bases de la séquence extraite. Vérifiez que vous n'avez pas fait d'erreur en comparant la taille de la séquence extraite avec celle que vous avez trouvée dans le fichier GenBank.
Construction d'une séquence complémentaire inverse¶
Toujours dans le même script, ajoutez la fonction construit_comp_inverse() qui prend en argument une séquence d'ADN sous forme de chaîne de caractères et qui renvoie la séquence complémentaire inverse (également sous la forme d'une chaîne de caractères).
On rappelle que construire la séquence complémentaire inverse d'une séquence d'ADN consiste à :
- Prendre la séquence complémentaire. C'est-à-dire à remplacer la base
apar la baset,tpara,cpargetgparc. - Prendre l'inverse. C'est-à-dire à que la première base de la séquence complémentaire devient la dernière base et réciproquement, la dernière base devient la première.
Pour vous faciliter le travail, ne travaillez que sur des séquences en minuscule.
Testez cette fonction avec les séquences atcg, AATTCCGG et gattaca.
Écriture d'un fichier FASTA¶
Toujours dans le même script, ajoutez la fonction ecrit_fasta() qui prend en argument un nom de fichier (sous forme de chaîne de caractères), un commentaire (sous forme de chaîne de caractères) et une séquence (sous forme de chaîne de caractères) et qui écrit un fichier FASTA. La séquence sera à écrire sur des lignes ne dépassant pas 80 caractères.
Pour rappel, un fichier FASTA suit le format suivant :
>commentaire
sequence sur une ligne de 80 caractères maxi
suite de la séquence .......................
suite de la séquence .......................
...
Testez cette fonction avec :
- nom de fichier :
test.fasta - commentaire :
mon commentaire -
séquence :
atcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatcgatc
Extraction des gènes¶
Toujours dans le même script, ajoutez la fonction extrait_genes() qui prend en argument la liste des gènes, la séquence nucléotidique complète (sous forme d'une chaîne de caractères) et le nom de l'organisme (sous forme d'une chaîne de caractères) et qui pour chaque gène :
- extrait la séquence du gène dans la séquence complète ;
- prend la séquence complémentaire inverse (avec la fonction
construit_comp_inverse()si le gène est antisens ; - enregistre le gène dans un fichier au format FASTA (avec la fonction
ecrit_fasta()) ; - affiche à l'écran le numéro du gène et le nom du fichier fasta créé.
La première ligne des fichiers FASTA sera de la forme :
Le numéro du gène sera un numéro consécutif depuis le premier gène jusqu'au dernier. Il n'y aura pas de différence de numérotation entre les gènes sens et les gènes antisens.
Testez cette fonction avec le fichier GenBank NC_001133.gbk.
Assemblage du script final¶
Pour terminer, modifiez le script genbank2fasta.py de façon à ce que le fichier GenBank à analyser (dans cet exemple NC_001133.gbk), soit entré comme argument du script.
Vous afficherez un message d'erreur si :
- le script
genbank2fasta.pyest utilisé sans argument, - le fichier fourni en argument n'existe pas.
Pour vous aider, n'hésitez pas à jeter un œil aux descriptions des modules sys et pathlib dans le chapitre 9 sur les modules.
Testez votre script ainsi finalisé.
27.2.4 Simulation d'un pendule¶
L'objectif de ce projet est de simuler un pendule simple en deux dimensions, puis de le visualiser à l'aide du module tkinter. Le projet peut s'avérer complexe. Tout d'abord, il y a l'aspect physique du projet. Nous allons faire ici tous les rappels de mécanique nécessaires à la réalisation du projet. Ensuite, il y a la partie tkinter qui n'est pas évidente au premier abord. Nous conseillons de bien séparer les deux parties. D'abord réaliser la simulation physique et vérifier qu'elle fonctionne (par exemple, en écrivant un fichier de sortie permettant cette vérification). Ensuite passer à la partie graphique tkinter si et seulement si la première partie est fonctionnelle.
Mécanique d'un pendule simple¶
Nous allons décrire ici ce dont nous avons besoin concernant la mécanique d'un pendule simple. Notamment, nous allons vous montrer comment dériver l'équation différentielle permettant de calculer la position du pendule à tout moment en fonction des conditions initiales. Cette page est largement inspirée de la page Wikipedia en anglais. Dans la suite, une grandeur représentée en gras, par exemple P, représente un vecteur avec deux composantes dans le plan 2D \((P_{x}, P_{y})\). Cette notation en gras est équivalente à la notation avec une flèche au dessus de la lettre. La même grandeur représentée en italique, par exemple P, représente le nombre scalaire correspondant. Ce nombre peut être positif ou négatif, et sa valeur absolue vaut la norme du vecteur.
Un pendule simple est représenté par une masse ponctuelle (la boule du pendule) reliée à un axe immobile par une tige rigide et sans masse. Le pendule simple est un système idéal. Ainsi, on néglige les effets de frottement et on considère le champ gravitationnel comme uniforme. La figure 2 montre un schéma du système ainsi qu'un bilan des forces agissant sur la masse. Les deux forces agissant sur la boule sont son poids P et la tension T due à la tige.
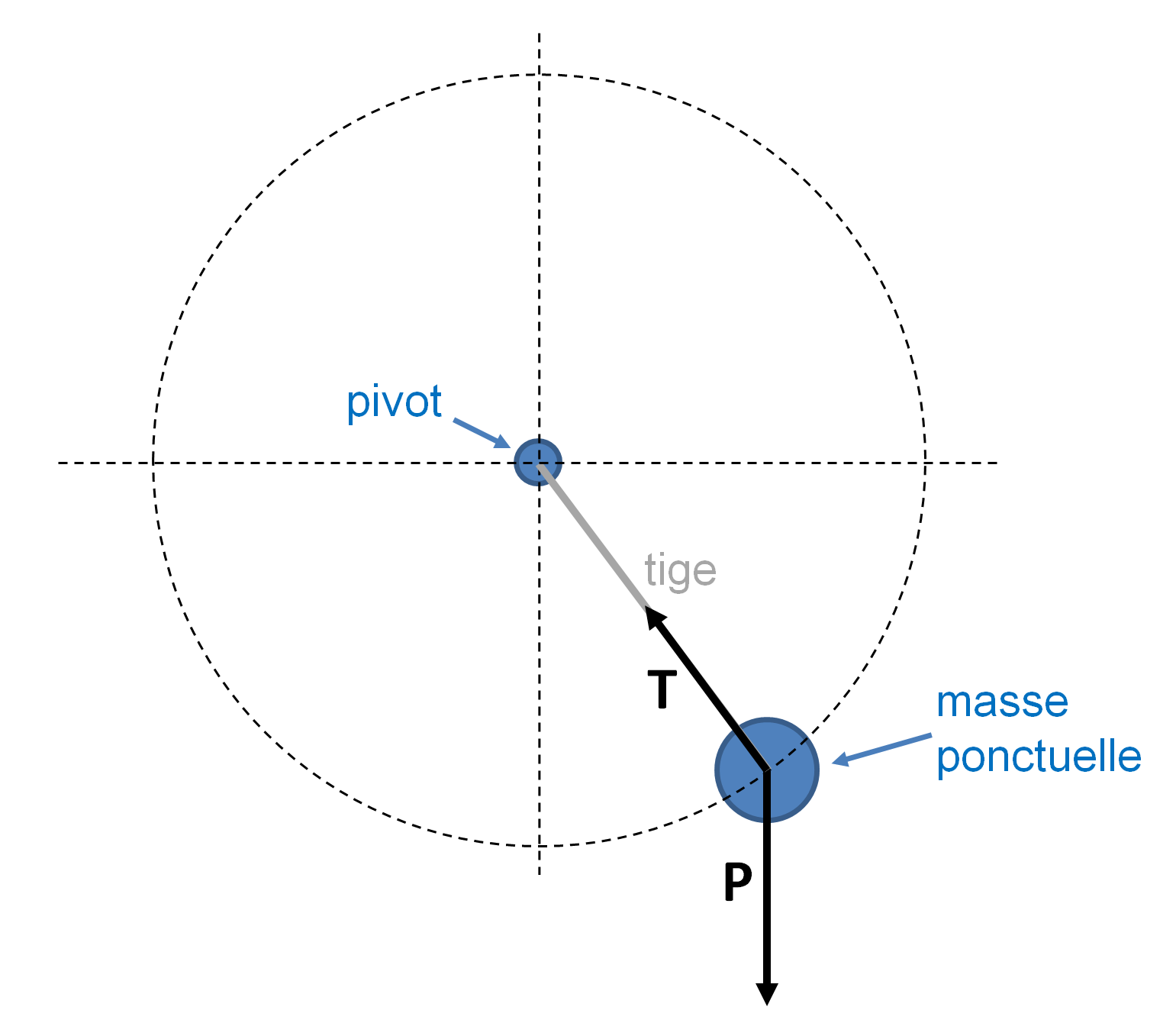
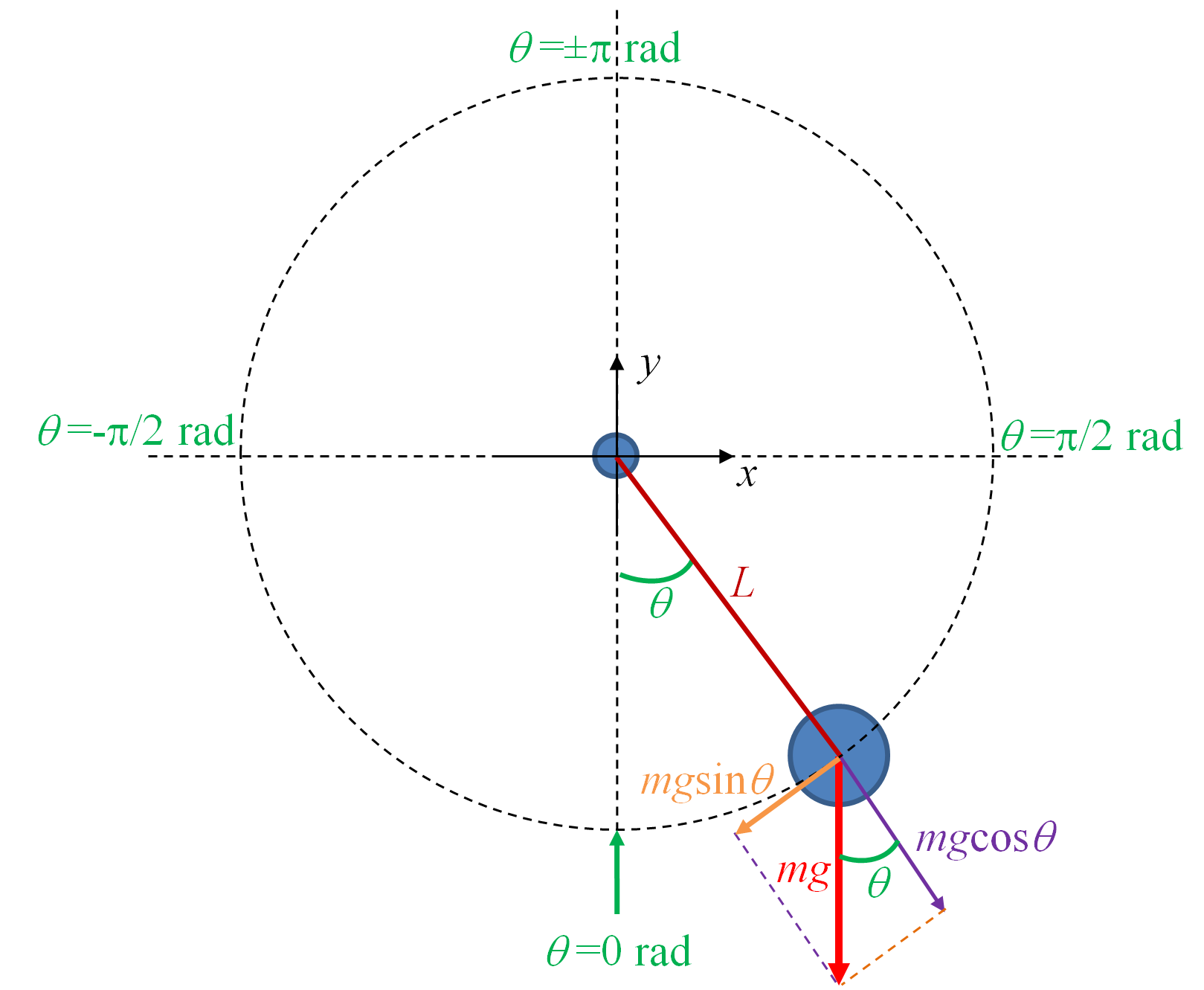
La figure 3 montre un schéma des différentes grandeurs caractérisant le pendule. La coordonnée naturelle pour définir la position du pendule est l'angle \(\theta\). Nous verrons plus tard comment convertir cet angle en coordonnées cartésiennes pour l'affichage dans un canvas tkinter. Nous choisissons de fixer \(\theta = 0\) lorsque le pendule est à sa position d'équilibre. Il s'agit de la position où la boule est au plus bas. C'est une position à laquelle le pendule ne bougera pas s'il n'a pas une vitesse préexistante. Nous choisissons par ailleurs de considérer \(\theta\) positif lorsque le pendule se balance à droite, et négatif de l'autre côté. g décrit l'accélération due à la gravité, avec \(\boldsymbol{\mathbf P} = m \boldsymbol{\mathbf g}\), ou si on raisonne en scalaire \(P = mg\). Les deux vecteurs représentant les composantes tangentielle et orthogonale au mouvement du pendule de P sont représentées sur le schéma (les annotations indiquent leur norme).
Si on déplace le pendule de sa position d'équilibre, il sera mû par la force F résultant de la tension T et de son poids P (cf. plus bas). Comme le système est considéré comme parfait (pas de frottement, gravité uniforme, etc.), le pendule ne s'arrêtera jamais. Si on le monte à \(\theta = +20\) deg et qu'on le lâche, le pendule redescendra en passant par \(\theta = 0\) deg, remontera de l'autre côté à \(\theta = -20\) deg, puis continuera de la sorte indéfiniment, grâce à la conservation de l'énergie dans un système fermé (c'est-à-dire sans « fuite » d'énergie).
Ici, on va tenter de simuler ce mouvement en appliquant les lois du mouvement de Newton et en résolvant les équations correspondantes numériquement. D'après la seconde loi de Newton, la force (F) agissant sur la boule est égale à sa masse (m) fois son accélération (a) :
Cette loi est exprimée ici dans le système de coordonnées cartésiennes (le plan à 2 dimensions). La force F et l'accélération a sont des vecteurs dont les composantes sont respectivement \((F_{x}, F_{y})\) et \((a_{x}, a_{y})\). La force F correspond à la somme vectorielle de T et P. La tige du pendule étant rigide, le mouvement de la boule est restreint sur le cercle de rayon égal à la longueur L de la tige (dessiné en pointillé). Ainsi, seule la composante tangentielle de l'accélération a sera prise en compte dans ce mouvement. Comment la calculer ? La force de tension T étant orthogonale au mouvement du pendule, celle-ci n'aura pas d'effet. De même, la composante orthogonale \(mgcos \theta\) due au poids P n'aura pas d'effet non plus. Au final, on ne prendra en compte que la composante tangentielle due au poids, c'est-à-dire \(mg sin \theta\) (cf. figure 3). Au final, on peut écrire l'expression suivante en raisonnant sur les valeurs scalaires :
Le signe \(-\) dans cette formule est très important. Il indique que l'accélération s'oppose systématiquement à \(\theta\). Si le pendule se balance vers la droite et que \(\theta\) devient plus positif, l'accélération tendra toujours à faire revenir la boule dans l'autre sens vers sa position d'équilibre à \(\theta = 0\). On peut faire un raisonnement équivalent lorsque le pendule se balance vers la gauche et que \(\theta\) devient plus négatif.
Si on exprime l'accélération en fonction de \(\theta\), on trouve ce résultat qui peut sembler peu intuitif au premier abord :
Le mouvement du pendule ne dépend pas de sa masse !
Idéalement, nous souhaiterions résoudre cette équation en l'exprimant en fonction de \(\theta\) seulement. Cela est possible en reliant \(\theta\) à la longueur effective de l'arc \(s\) parcourue par le pendule :
Pour bien comprendre cette formule, souvenez-vous de la formule bien connue du cercle \(l = 2 \pi r\) (où l est la circonférence, et r le rayon) ! Elle relie la valeur de \(\theta\) à la distance de l'arc entre la position actuelle de la boule et l'origine (à \(\theta = 0\)). On peut donc exprimer la vitesse du pendule en dérivant \(s\) par rapport au temps \(t\) :
On peut aussi exprimer l'accélération a en dérivant l'arc s deux fois par rapport à t :
A nouveau, cette dernière formule exprime l'accélération de la boule lorsque le mouvement de celle-ci est restreint sur le cercle pointillé. Si la tige n'était pas rigide, l'expression serait différente.
Si on remplace a dans la formule ci-dessus, on trouve :
Soit en remaniant, on trouve l'équation différentielle en \(\theta\) décrivant le mouvement du pendule :
Dans la section suivante, nous allons voir comment résoudre numériquement cette équation différentielle.
Résolution de l'équation différentielle du pendule¶
Il existe de nombreuses méthodes numériques de résolution d'équations différentielles. L'objet ici n'est pas de faire un rappel sur toutes ces méthodes ni de les comparer, mais juste d'expliquer une de ces méthodes fonctionnant efficacement pour simuler notre pendule.
Nous allons utiliser la méthode semi-implicite d'Euler. Celle-ci est relativement intuitive à comprendre.
Commençons d'abord par calculer l'accélération angulaire \(a_{\theta}\) au temps t en utilisant l'équation différentielle précédemment établie :
L'astuce sera de calculer ensuite la vitesse angulaire au pas suivant \(t + \delta t\) grâce à la relation :
Cette équation est ni plus ni moins qu'un remaniement de la définition de l'accélération, à savoir, la variation de vitesse par rapport à un temps. Cette vitesse \(v_{\theta}(t+\delta t)\) permettra au final de calculer \(\theta\) au temps \(t + \delta t\) (c'est-à-dire ce que l'on cherche !) :
Dans une réalisation algorithmique, il suffira d'initialiser les variables de notre système puis de faire une boucle sur un nombre de pas de simulation. A chaque pas, on calculera \(a_{\theta}(t)\), puis \(v_{\theta}(t+\delta t)\) et enfin \(\theta (t + \delta t)\) à l'aide des formules ci-dessus.
L'initialisation des variables pourra ressembler à cela :
L <- 1 # longueur tige en m
g <- 9.8 # accélération gravitationnelle en m/s^2
t <- 0 # temps initial en s
dt <- 0.05 # pas de temps en s
# conditions initiales
theta <- pi / 4 # angle initial en rad
dtheta <- 0 # vitesse angulaire initiale en rad/s
afficher_position_pendule(t, theta) # afficher position de départ
L'initialisation des valeurs de theta et dtheta est très importante, car elle détermine le comportement du pendule. Nous avons choisi ici d'avoir une vitesse angulaire nulle et un angle de départ du pendule \(\theta = \pi / 4\) rad \(= 45\) deg. Le pas dt est également très important, c'est lui qui déterminera l'erreur faite sur l'intégration de l'équation différentielle. Plus ce pas est petit, plus on est précis, mais plus le calcul sera long. Ici, on choisit un pas dt de 0.05 s qui constitue un bon compromis.
À ce stade, vous avez tous les éléments pour tester votre pendule. Essayez de réaliser un petit programme python pendule_basic.py qui utilise les conditions initiales ci-dessus et simule le mouvement du pendule. À la fin de cette rubrique, nous proposons une solution en langage algorithmique. Essayez dans un premier temps de le faire vous-même. À chaque pas, le programme écrira le temps \(t\) et l'angle \(\theta\) dans un fichier pendule_basic.dat. Dans les équations, \(\theta\) doit être exprimé en radian, mais nous vous conseillons de convertir cet angle en degré dans le fichier (plus facile à comprendre pour un humain !). Une fois ce fichier généré, vous pourrez observer le graphe correspondant avec matplotlib en utilisant le code suivant :
import matplotlib.pyplot as plt
import numpy as np
# La fonction np.genfromtxt() renvoie un array à 2 dim.
array_data = np.genfromtxt("pendule_basic.dat")
# col 0: t, col 1: theta
t = array_data[:,0]
theta = array_data[:,1]
# Figure.
fig, ax = plt.subplots(figsize=(8, 8))
mini = min(theta) * 1.2
maxi = max(theta) * 1.2
ax.set_xlim(0, max(t))
ax.set_ylim(mini, maxi)
ax.set_xlabel("t (s)")
ax.set_ylabel("theta (deg)")
ax.plot(t, theta)
fig.savefig("pendule_basic.png")
Si vous observez une sinusoïde, bravo, vous venez de réaliser votre première simulation de pendule ! Vous avez maintenant le « squelette » de votre « moteur » de simulation. N'hésitez pas à vous amuser avec d'autres conditions initiales. Ensuite vous pourrez passer à la rubrique suivante.
Si vous avez bloqué dans l'écriture de la boucle, voici à quoi elle pourrait ressembler en langage algorithmique :
tant qu'on n'arrête pas le pendule:
# acc angulaire au tps t (en rad/s^2)
d2theta <- -(g/L) * sin(theta)
# v angulaire mise à jour de t -> t + dt
dtheta <- dtheta + d2theta * dt
# theta mis à jour de t -> t + dt
theta <- theta + dtheta * dt
# t mis à jour
t <- t + dt
# mettre à jour l'affichage
afficher_position_pendule(t, theta)
Constructeur de l'application en tkinter¶
Nous allons maintenant construire l'application tkinter en vous guidant pas à pas. Il est bien sûr conseillé de relire le chapitre 25 sur Fenêtres graphiques et Tkinter (en ligne) avant de vous lancer dans cette partie.
Comme expliqué largement dans les chapitres 23 Avoir la classe avec les objets et 24 Avoir plus la classe avec les objets (en ligne), nous allons construire l'application avec une classe. Le programme principal sera donc très allégé et se contentera d'instancier l'application, puis de lancer le gestionnaire d'événements :
if __name__ == "__main__":
"""Programme principal (instancie la classe principale, donne un
titre et lance le gestionnaire d'événements)
"""
app_pendule = AppliPendule()
app_pendule.title("Pendule")
app_pendule.mainloop()
Ensuite, nous commençons par écrire le constructeur de la classe. Dans ce constructeur, nous aurons une section initialisant toutes les variables utilisées pour simuler le pendule (voir rubrique précédente), puis, une autre partie générant les widgets et tous les éléments graphiques. Nous vous conseillons vivement de bien les séparer, et surtout de mettre des commentaires pour pouvoir s'y retrouver. Voici un « squelette » pour vous aider :
class AppliPendule(tk.Tk):
def __init__(self):
# Instanciation de la classe Tk.
tk.Tk.__init__(self)
# Ici vous pouvez définir toutes les variables
# concernant la physique du pendule.
self.theta = np.pi / 4 # valeur intiale theta
self.dtheta = 0 # vitesse angulaire initiale
[...]
self.g = 9.8 # cst gravitationnelle en m/s^2
[...]
# Oci vous pouvez construire l'application graphique.
self.canv = tk.Canvas(self, bg='gray', height=400, width=400)
# Création d'un boutton demarrer, arreter, quitter.
# Pensez à placer les widgets avec .pack()
[...]
La figure 1-apercu vous montre un aperçu de ce que l'on voudrait obtenir.
Pour le moment, vous pouvez oublier la réglette fixant la valeur initiale de \(\theta\), les labels affichant la valeur de \(\theta\) et \(v_{\theta}\) ainsi que les points violets « laissés en route » par le pendule. De même, nous dessinerons le pivot, la boule et la tige plus tard. À ce stade, il est fondamental de tout de suite lancer votre application pour vérifier que les widgets sont bien placés. N'oubliez pas, un code complexe se teste au fur et à mesure lors de son développement.
Pour éviter un message d'erreur si toutes les méthodes n'existe pas encore, vous pouvez indiquer command=self.quit pour chaque bouton (vous le changerez après).
Créations des dessins dans le canvas¶
Le pivot et la boule pourront être créés avec la méthode .create_oval(), la tige le sera avec la méthode .create_line(). Pensez à créer des variables pour la tige et la boule lors de l'instanciation car celles-ci bougeront par la suite.
Comment placer ces éléments dans le canvas ? Vous avez remarqué que lors de la création de ce dernier, nous avons fixé une dimension de 400 \(\times\) 400 pixels. Le pivot se trouve au centre, c'est-à-dire au point \((200, 200)\). Pour la tige et la boule, il sera nécessaire de connaître la position de la boule dans le repère du canvas. Or, pour l'instant, nous définissons la position de la boule avec l'angle \(\theta\). Il va donc nous falloir convertir \(\theta\) en coordonnées cartésiennes \((x, y)\) dans le repère mathématique défini dans la figure 3, puis dans le repère du canvas \((x_{c}, y_{c})\) (cf. rubrique suivante).
Conversion de \(\theta\) en coordonnées \((x, y)\)¶
Cette étape est relativement simple si on considère le pivot comme le centre du repère. Avec les fonctions trigonométriques sin() et cos(), vous pourrez calculer la position de la boule (voir l'exercice sur la spirale dans le chapitre 7 Fichiers). Faites attention toutefois aux deux aspects suivants :
- la trajectoire de la boule suit les coordonnées d'un cercle de rayon L (si on choisit L = 1 m, ce sera plus simple) ;
- nous sommes décalés par rapport au cercle trigonométrique classique ; si on considère L = 1 m :
- quand \(\theta = 0\), on a le point \((0, -1)\) (pendule en bas) ;
- quand \(\theta = + \pi / 2 = 90\) deg, on a \((1, 0)\) (pendule à droite) ;
- quand \(\theta = - \pi / 2 = -90\) deg, on a \((-1, 0)\) (pendule à gauche) ;
- quand \(\theta = \pm \pi = \pm 180\) deg, on a \((0, 1)\) (pendule en haut).
La figure 3 montre graphiquement les valeurs de \(\theta\).
Si vous n'avez pas trouvé, voici la solution :
Conversion des coordonnées \((x, y)\) en \((x_c, y_c)\)¶
Il nous faut maintenant convertir les coordonnées naturelles mathématiques du pendule \((x, y)\) en coordonnées dans le canvas \((x_{c}, y_{c})\). Plusieurs choses sont importantes pour cela :
- le centre du repère mathématique \((0, 0)\) a la coordonnée \((200, 200)\) dans le canvas ;
- il faut choisir un facteur de conversion : par exemple, si on choisit L = 1 m, on peut proposer le facteur 1 m \(\rightarrow\) 100 pixels ;
- l'axe des ordonnées dans le canvas est inversé par rapport au repère mathématique.
Dans votre classe, cela peut être une bonne idée d'écrire une méthode qui réalise cette conversion. Celle-ci pourrait s'appeler par exemple map_realcoor2canvas().
Si vous n'avez pas trouvé, voici la solution :
self.conv_factor = 100
self.x_c = self.x*self.conv_factor + 200
self.y_c = -self.y*self.conv_factor + 200
Gestion des boutons¶
Il reste maintenant à gérer les boutons permettant de démarrer / stopper le pendule. Pour cela il faudra créer trois méthodes dans notre classe :
- La méthode
.start(): met en mouvement le pendule ; si le pendule n'a jamais été en mouvement, il part de son point de départ ; si le pendule avait déjà été en mouvement, celui-ci repart d'où on l'avait arrêté (avec la vitesse qu'il avait à ce moment-là). - La méthode
.stop(): arrête le mouvement du pendule. - La méthode
.move(): gère le mouvement du pendule (génère les coordonnées du pendule au pas suivant).
Le bouton « Démarrer » appellera la méthode .start(), le bouton « Arrêter » appellera la méthode .stop() et le bouton « Quitter » quittera l'application. Pour lier une action au clic d'un bouton, on se souvient qu'il faut donner à l'argument par mot-clé command une callback (c'est-à-dire le nom d'une fonction ou méthode sans les parenthèses) :
btn1 = tk.Button(self, text="Quitter", command=self.quit)btn2 = tk.Button(self, text="Demarrer", command=self.start)btn3 = tk.Button(self, text="Arrêter", command=self.stop)
Ici, self.start() et self.stop() sont des méthodes que l'on doit créer, self.quit() pré-existe lorsque la fenêtre tkinter est créée.
Nous vous proposons ici une stratégie inspirée du livre de Gérard Swinnen. Créons d'abord un attribut d'instance self.is_moving dans le constructeur. Celui-ci va nous servir de « drapeau » pour définir le mouvement du pendule. Il contiendra un entier positif ou nul. Lorsque ce drapeau sera égal à 0, le pendule sera immobile. Lorsqu'il sera > 0, le pendule sera en mouvement. Ainsi :
- la méthode
.start()ajoutera 1 àself.is_moving. Siself.is_movingest égal à 1 alors la méthodeself.move()sera appelée ; - la méthode
.stop()mettra la valeur deself.is_movingà 0.
Puisque .start() ajoute 1 à self.is_moving, le premier clic sur le bouton « Démarrer » appellera la méthode .move() car self.is_moving vaudra 1. Si l'utilisateur appuie une deuxième fois sur le bouton « Démarrer », self.is_moving vaudra 2, mais n'appellera pas .move() une deuxième fois ; cela sera vrai pour tout clic ultérieur de l'utilisateur sur ce bouton. Cette astuce évite des appels concurrents de la méthode .move().
Le coeur du programme : la méthode .move()¶
Il nous reste maintenant à générer la méthode .move() qui meut le pendule. Pour cela vous pouvez vous inspirer de la rubrique Un canvas animé dans une classe du chapitre 25 Fenêtres graphiques et Tkinter (en ligne).
Cette méthode va réaliser un pas de simulation de \(t\) à \(t+\delta t\). Il faudra ainsi réaliser dans l'ordre :
- Calculer la nouvelle valeur de \(\theta\) (
self.theta) au pas \(t+\delta t\) comme nous l'avons fait précédemment avec la méthode semi-implicite d'Euler. - Convertir la nouvelle valeur de \(\theta\) (
self.theta) en coordonnées cartésiennes dans le repère du pendule (self.xetself.y). - Convertir ces coordonnées cartésiennes dans le repère du Canvas (
self.x_cetself.y_c). - Mettre à jour le dessin de la baballe et de la tige avec la méthode
self.canv.coords(). - Incrémenter le pas de temps.
- Si le drapeau
self.is_movingest supérieur à 0, la méthodeself.move()est rappelée après 20 millisecondes (Conseil: la méthode.after()est votre amie).
Ressources complémentaires¶
Si vous êtes arrivé jusqu'ici, bravo, vous pouvez maintenant admirer votre superbe pendule en mouvement :-) !
Voici quelques indications si vous voulez aller un peu plus loin.
Si vous souhaitez mettre une réglette pour modifier la position de départ du pendule, vous pouvez utiliser la classe tk.Scale(). Si vous souhaitez afficher la valeur de \(\theta\) qui se met à jour au fur et à mesure, il faudra instancier un objet avec la classe tk.StringVar(). Cet objet devra être passé à l'argument textvariable lors de la création de ce Label avec tk.Label(). Ensuite, vous pourrez mettre à jour le texte du Label avec la méthode self.instance_StringVar.set().
Pour le fun, si vous souhaitez laisser une « trace » du passage du pendule avec des points colorés, vous pouvez utiliser tout simplement la méthode self.canv.create_line() et créer une ligne d'un pixel de hauteur et de largeur pour dessiner un point. Pour améliorer l'esthétique, vous pouvez faire en sorte que ces points changent de couleur aléatoirement à chaque arrêt / redémarrage du pendule.
27.3 Scripts de correction¶
Voici les scripts corrigés pour les différents mini-projets.
- Prenez le temps de chercher par vous-même avant de télécharger les scripts de correction.
- Nous proposons une correction. D'autres solutions sont possibles.
- Mots anglais dans le protéome humain : words_in_proteome.py
- Genbank2fasta (sans expression régulière) : genbank2fasta_sans_regex.py
- Genbank2fasta (avec expressions régulières) : genbank2fasta_avec_regex.py
- Simulation d'un pendule version simple : tk_pendule.py
- Simulation d'un pendule++ (avec réglette et affichage se mettant à jour) : tk_pendule.py